ChatGPTを使い始めてから、AIにより興味を持ちまして、画像作成AI「Stable Diffusion」も触ってみました。
最初は全然思うように画像が生成されなかったものの、Promptに入れると良さそうなキーワードを見つけてからはクオリティを上げることができました。
イラスト風にするなど、いくつかお気に入りのキーワードと実例をご紹介します。
目次
Stable DiffusionのおすすめPrompt
Stable Diffusionを使うときのコツについては、下記の記事を参考にしました。
Promptについてたくさん羅列されてるので、基本的にはそちらのサイトからピックアップして使っています。
今のところ気に入ってるのはイラスト風にする「digital painting」です。写真っぽい画像だと作られた感が強いので、イラストの方が使い勝手良いです。
Stable DiffusionでPromptを加えていった事例
Stable Diffusionで画像生成する際に、Promptを1パターンずつ足していってどのように変化していくかご覧ください。
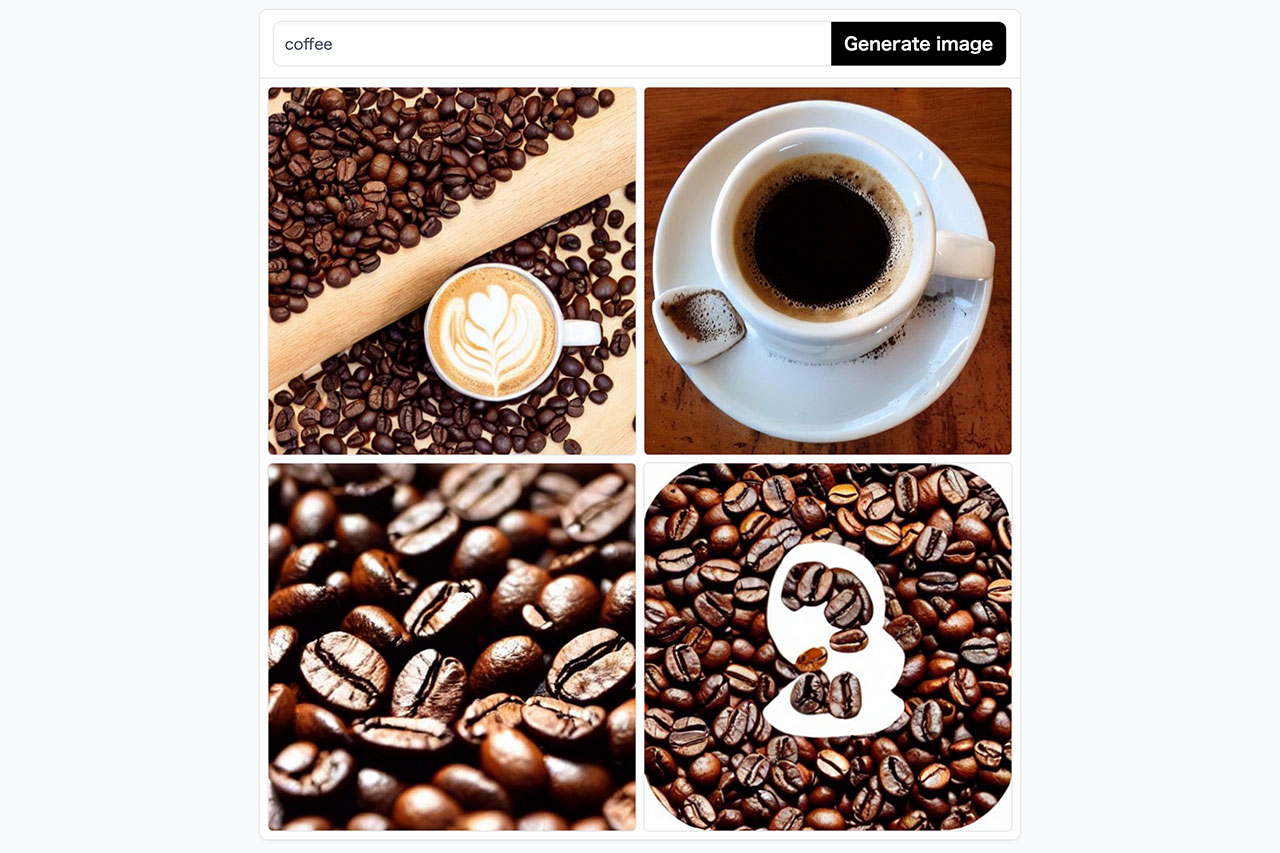
まずは作りたい画像のキーワードのみを入れた例。coffeeと単語だけ入れると、コーヒー豆とコーヒーカップが出てしまったりとちょっとブレがあります。
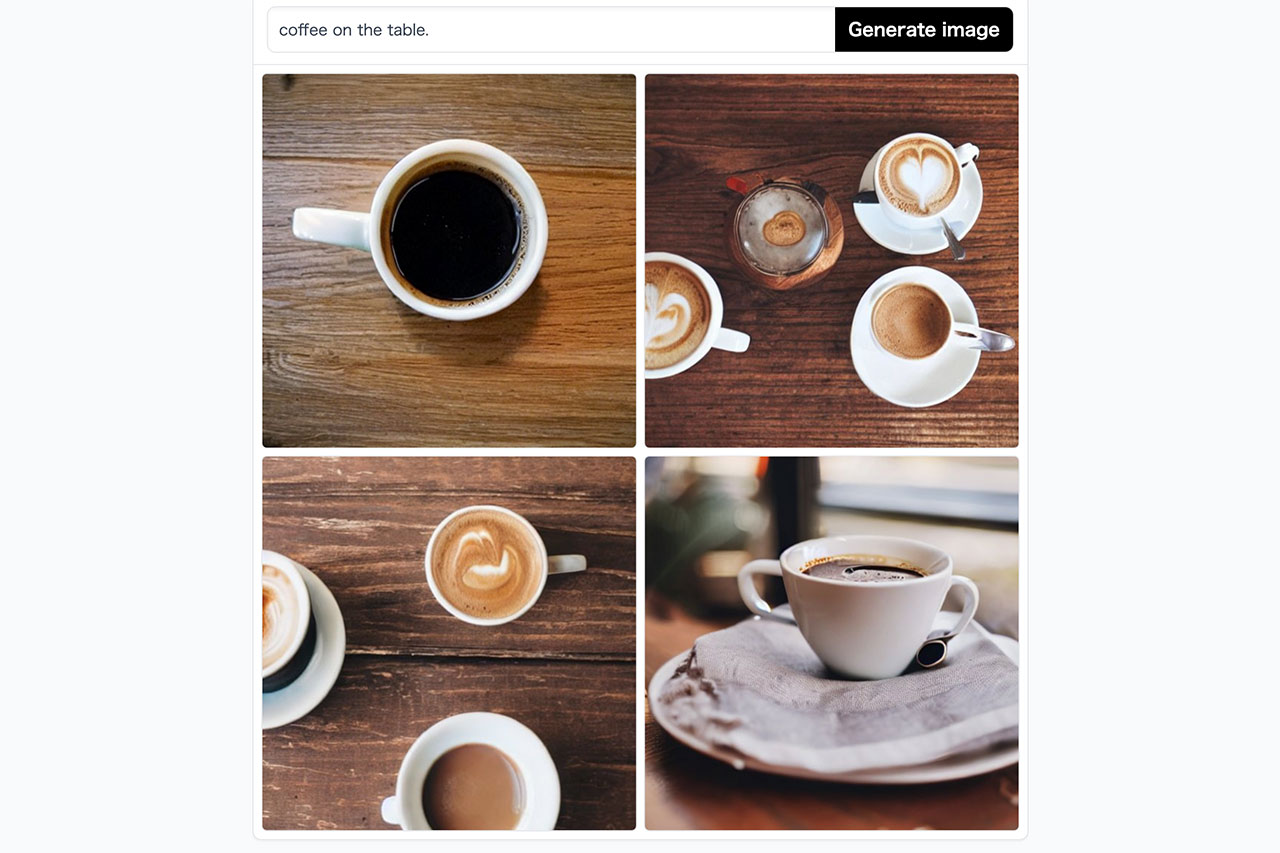
「coffee on the table.」とシチュエーションを絞ると、より詳細な画像を出力してくれます。この辺りはシンプルに文章の話です。
ここからはStable Diffusionへの指令のような、ピンポイントで刺さるキーワードです。まずは先ほど紹介した「digital painting」でイラスト風に。

「highly detailed」を追記すると、雑なイラストが少なくなったような気がします。

「cinematic lighting」で照明を追加。雰囲気が出ました。

その後いろいろ試行錯誤して、この画像2枚はかなり気に入りました。

こんな具合に、Promptに追加するキーワード次第でコントロールしやすくなるので、あとはいつも通りChatGPTにStable Diffusionで使えるPromptを聞きながら作業進めたら良さそうです。
画像の事例からPromptを拾ってこれる「Lexica」も便利
Lexicaは、Stable Diffusionで生成された画像が一覧表示されていて、ワンクリックでPromptをコピーできるサイトです。
僕が使ってみたところ、こんなにクオリティの高い画像は生成できなかったんですが、それでもPromptの使い方のコツは掴みやすいと思いますし、そこからキーワードを足したり引いたりすれば結構いい感じの画像は作れました。
他の人の使い方を学ぶサイトだと捉えると、かなり勉強になります。
プロンプトの入力に慣れない方はImage to Image機能がおすすめ
テキストから画像を作るText to Image機能は、プロンプトの入力のコツをつかむのが大変なので、思った通りの画像が作れない方は「画像から新たな画像を生み出すImage to Image機能」がおすすめです。
Stable Diffusion Reimagineを使った事例はこちらの記事をどうぞ。

Leonardo.AiのImage to Image機能も優秀で、たとえばこちらのようにイラストから写真風の画像を簡単に作り出すことができます。

詳細はこちらの動画をどうぞ。
最後に
Stable Diffusionは本当に便利だし可能性があるツールです。ブログのアイキャッチ画像や、YouTubeのサムネなど、画像を作る機会が増えるほど作業工数減らしたくなるので、AIに助けてもらいながらクオリティも担保しつつやっていきます。
AIを使えば使うほど、AIを使う側の知識や技術が必要だと感じます。また、その知識や技術をサポートしてくれるのがAIであるChatGPTだったりして、AIに使われる側ではなくAIを使いこなす人間になるためにどうしたらいいか、日々考えていこうと思います。