ブラウザ上で簡単にバナーやサムネ画像などを作れるサービスCanvaには、以前からText-to-Imageの機能がついていましたが、2023年2月10日に日本語の入力に対応したということで、早速触ってみました。
オープンソースの画像生成AI 「Stable Diffusion」を使っていることもあり生成される画像の精度はかなり高く、プロンプトの入力が日本語でもできるようになったことで、日本語母語話者としては直感的に入力できてありがたいです。
目次
CanvaのText-to-Imageの使い方
それではCanvaの画像生成画面にて、日本語を使ってAIに画像を生成してもらう手順をご覧ください。
こちらがCanvaの画面です。
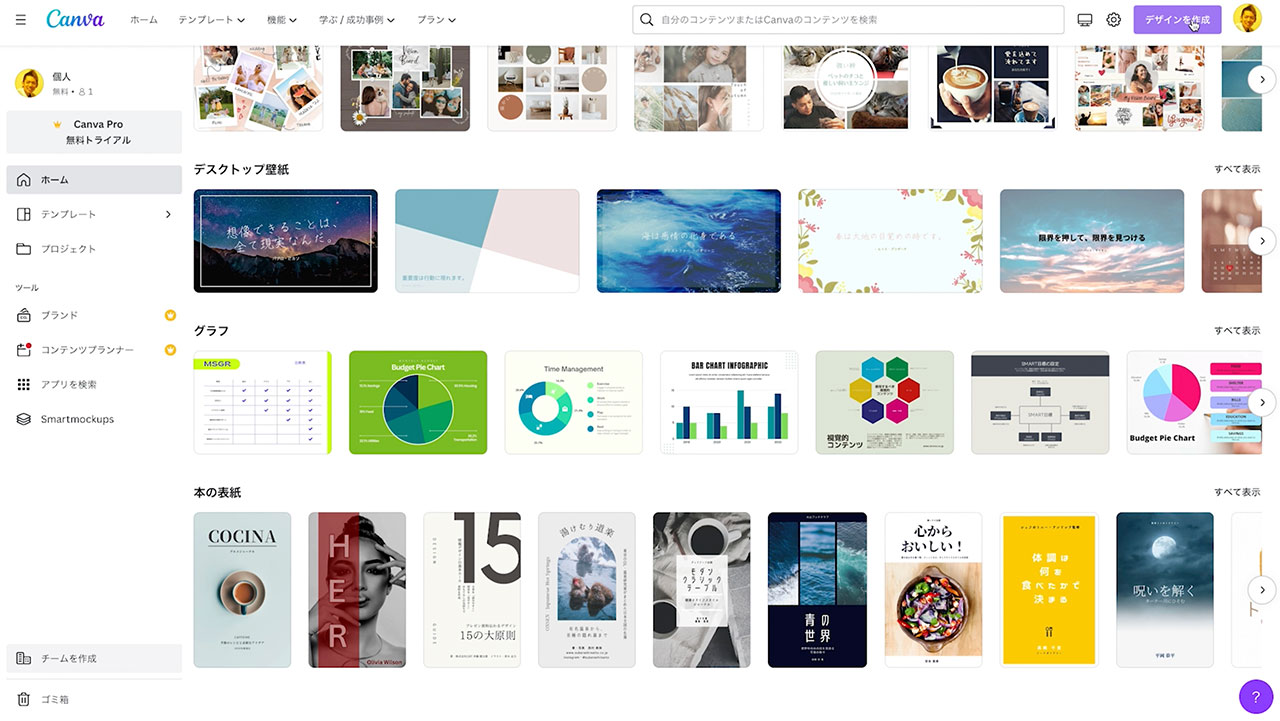
右上の「デザインを作成」ボタンから、今回は一例としてYouTubeサムネイルを選択しておきます。
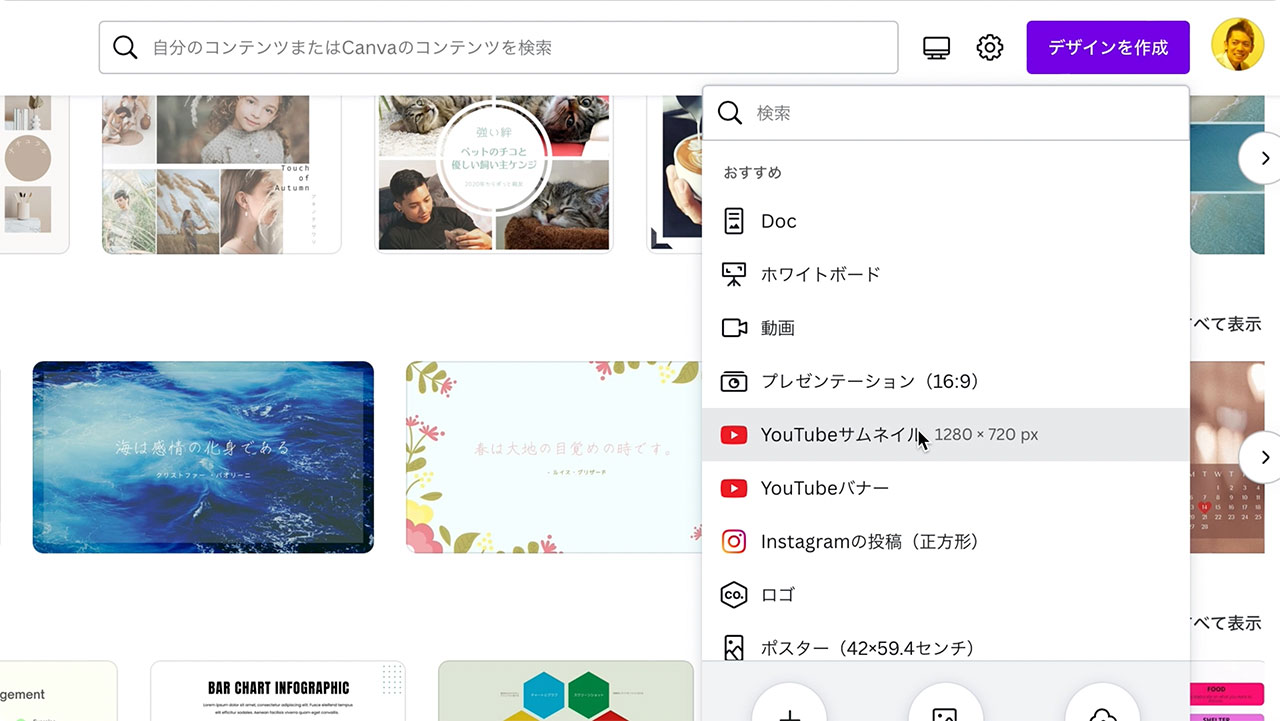
CanvaのText-to-Image機能はアプリの中に入っています。(最初どこにあるのか分からなくて、アプリの中に入って下の方までスクロールしちゃいました。)
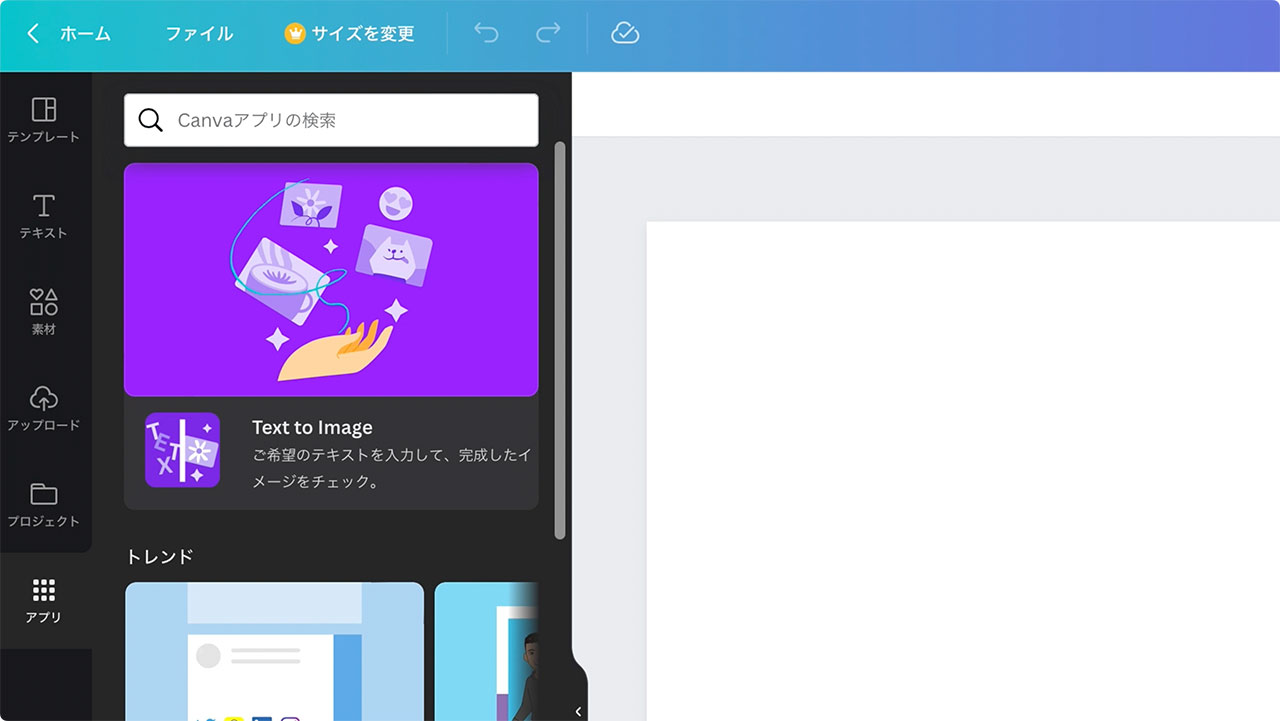
CanvaのText-to-Image機能を日本語入力で使ってみる
それでは日本語で指令を出してAIに画像を作ってもらいましょう。
例1 ギターを弾いている少年
最初に入力したプロンプトは「暗い部屋でソファーに座った少年がギターを弾いている」としてみました。
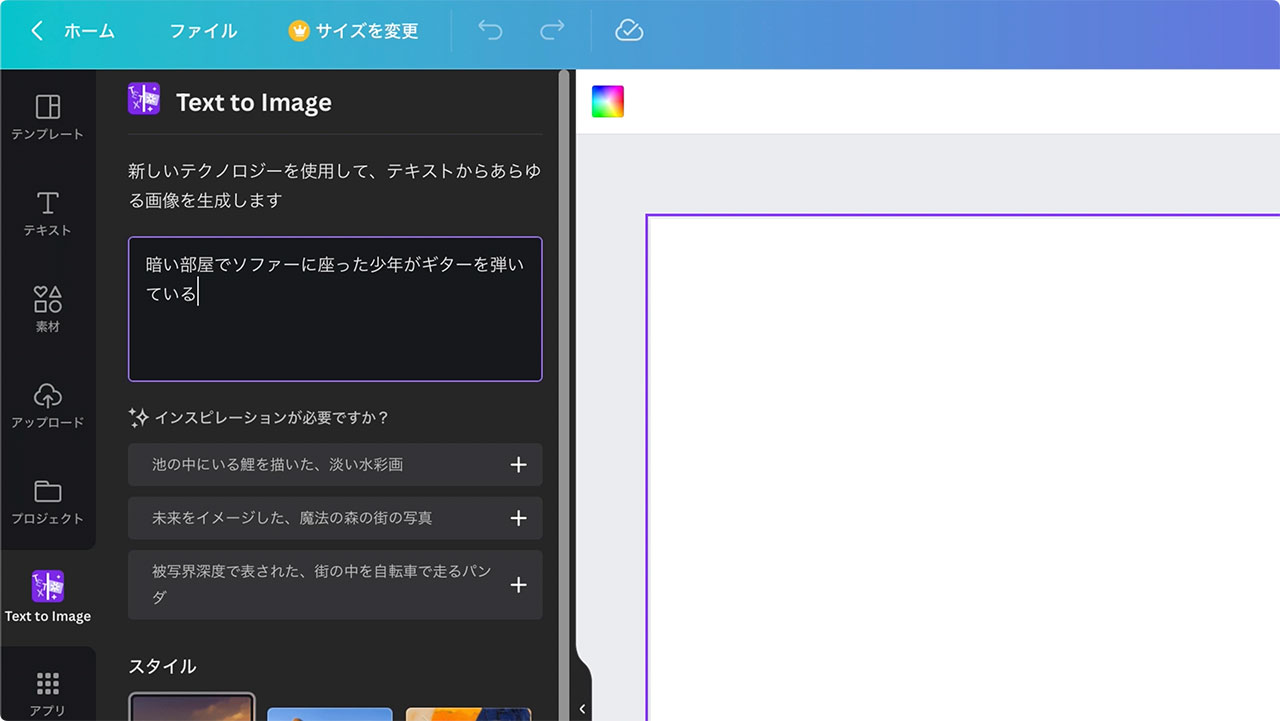
生成された画像がこちらです。
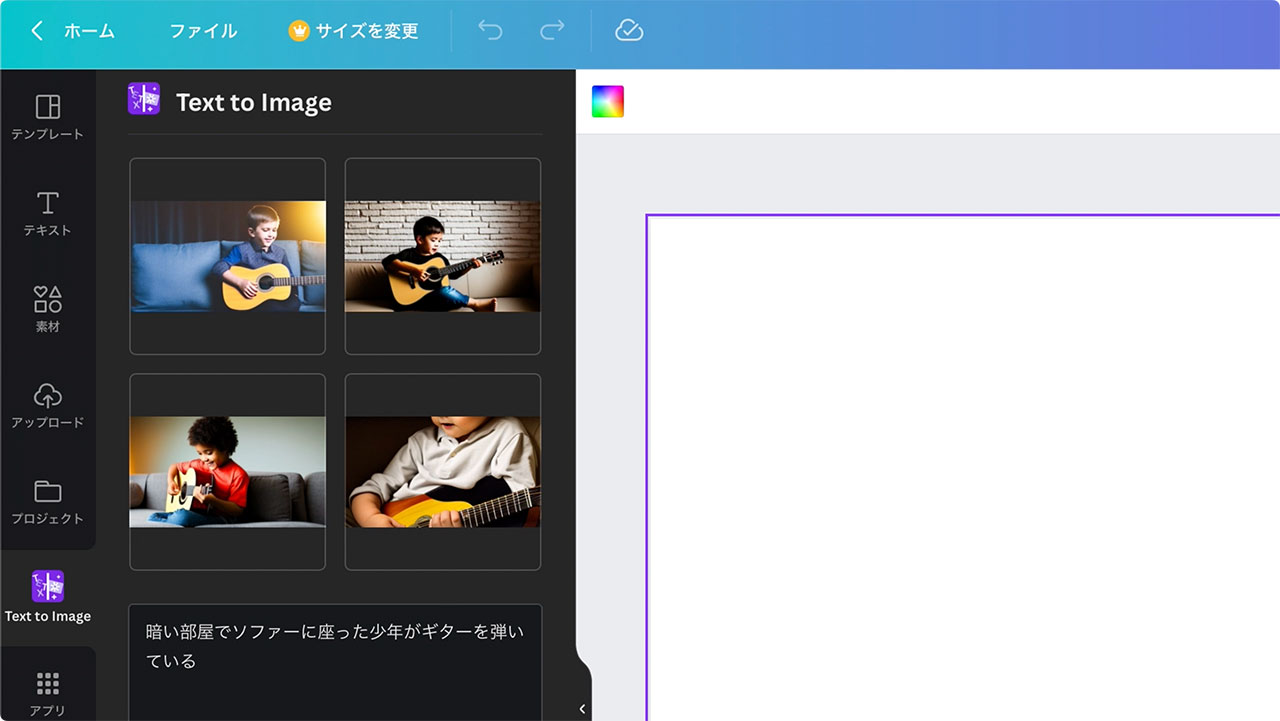
「暗い部屋」「ソファ」「少年」「ギター」など、複数の要素をきちんと理解してくれてイメージした通りの画像を作ってくれました。
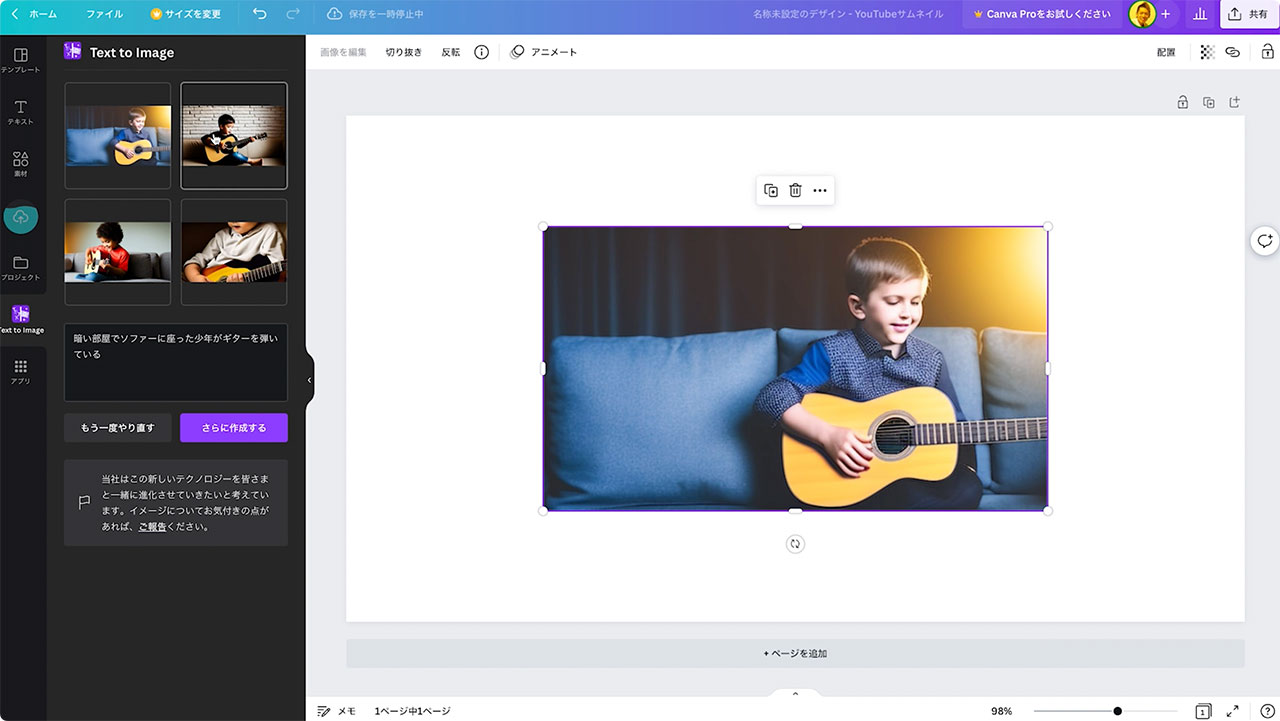
例2 パソコンを触っている人の後ろ姿
次に「ハッカーがパソコンをいじっていてそのハッカーの顔は後ろ姿で見えない」と入力してみました。
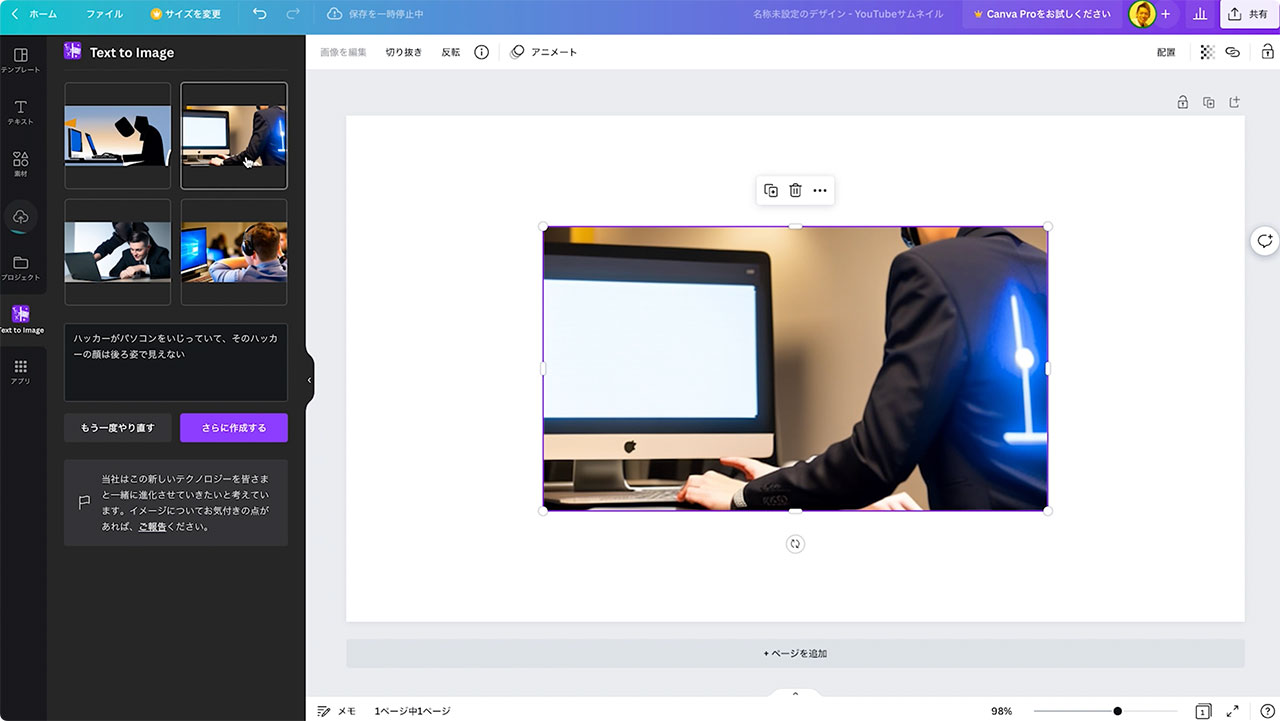
パソコンを触っている人を後ろから撮影したような画角の画像が欲しかったのでこちらもイメージ通りです。
例3 パソコンを横から水平に撮影したような写真(失敗例)
もう少しカメラの画角を調整できるか試してみたかったので「パソコンの画面にプログラミング言語が表示されている、パソコンはデスクの上に置いてあってそれを水平に見ている」と入れてみました。
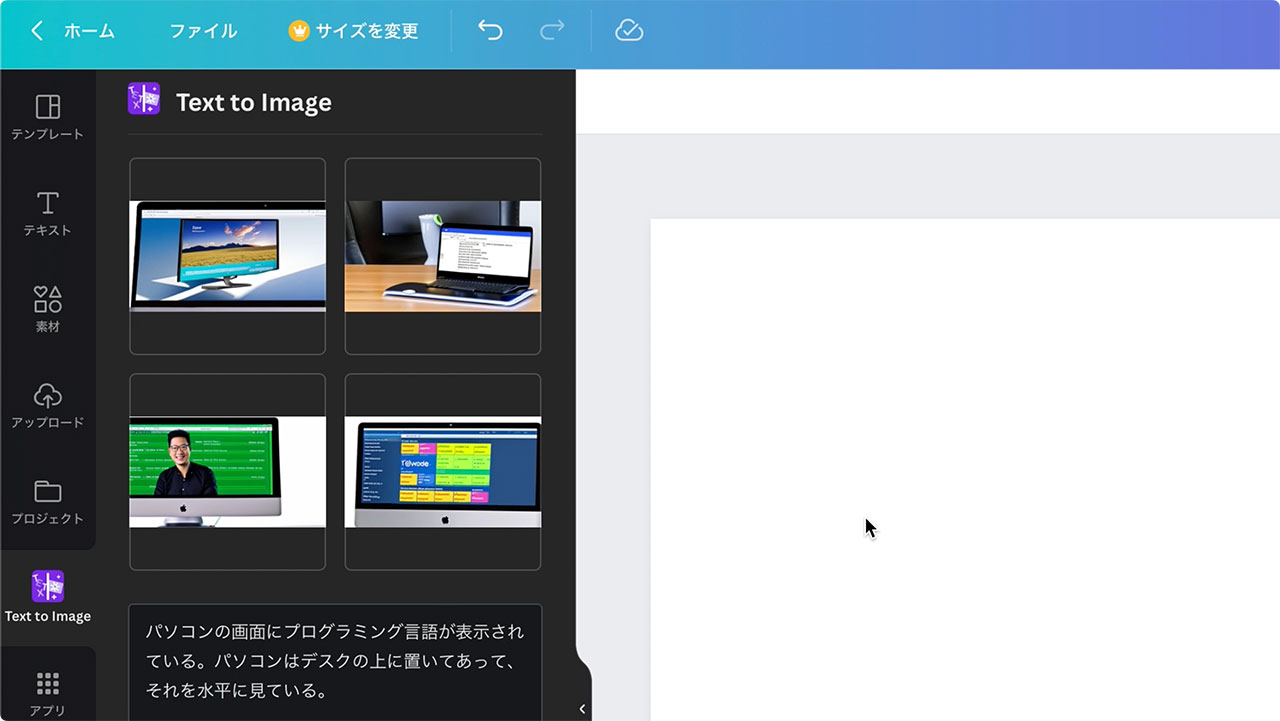
カメラの画角はなかなかコントロールが難しくて、日本語なら水平のキーワードでいけると思ったのですが、もう少し指令の出し方は工夫が必要ですね。
例4 劇場の客席
ブログでお笑い関連の記事を書くことがあり、その時に使ういい感じの画像が見つからないことが多いので、劇場の内観っぽい画像を生成してみます。
「劇場のシート、お客さんはいない、劇場の舞台から客席を見ている視点」と入れてみました。これはだいぶイメージ通りにできました。
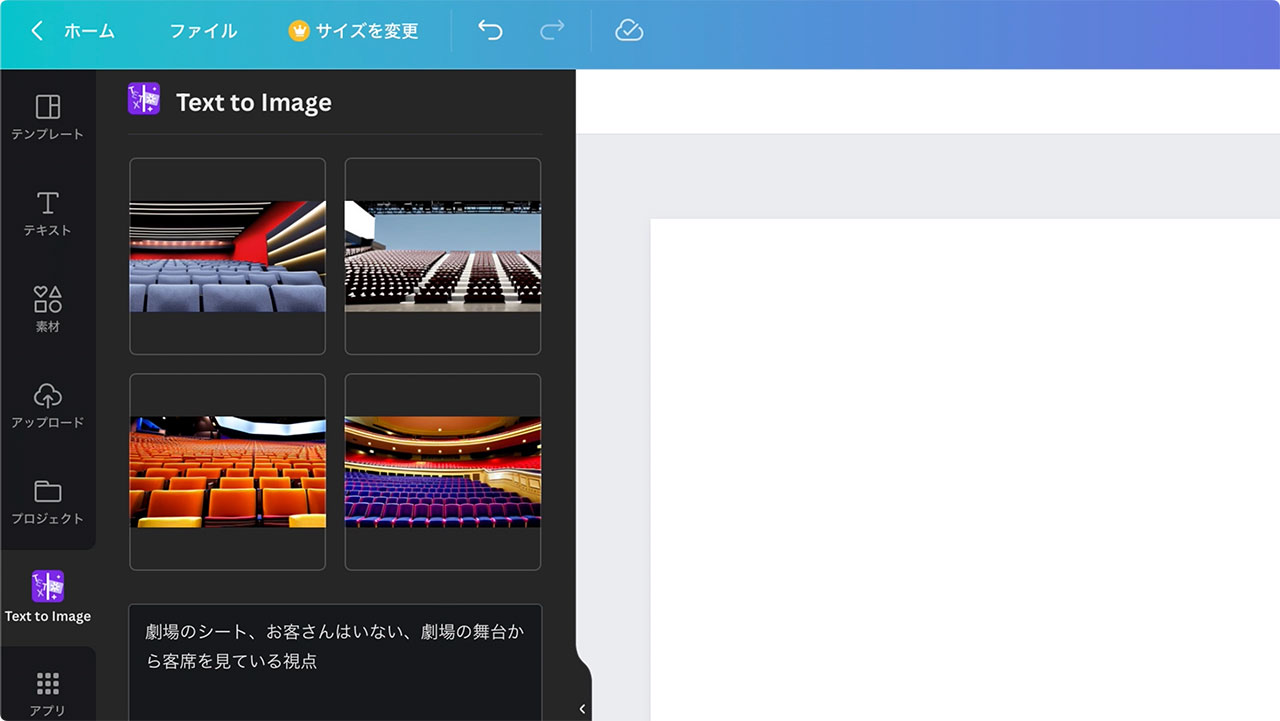
この画像を背景に敷いてテキストを入れてみます。
テンプレートから好みのものを選び、
画像を差し替えるだけとめちゃめちゃ簡単です。
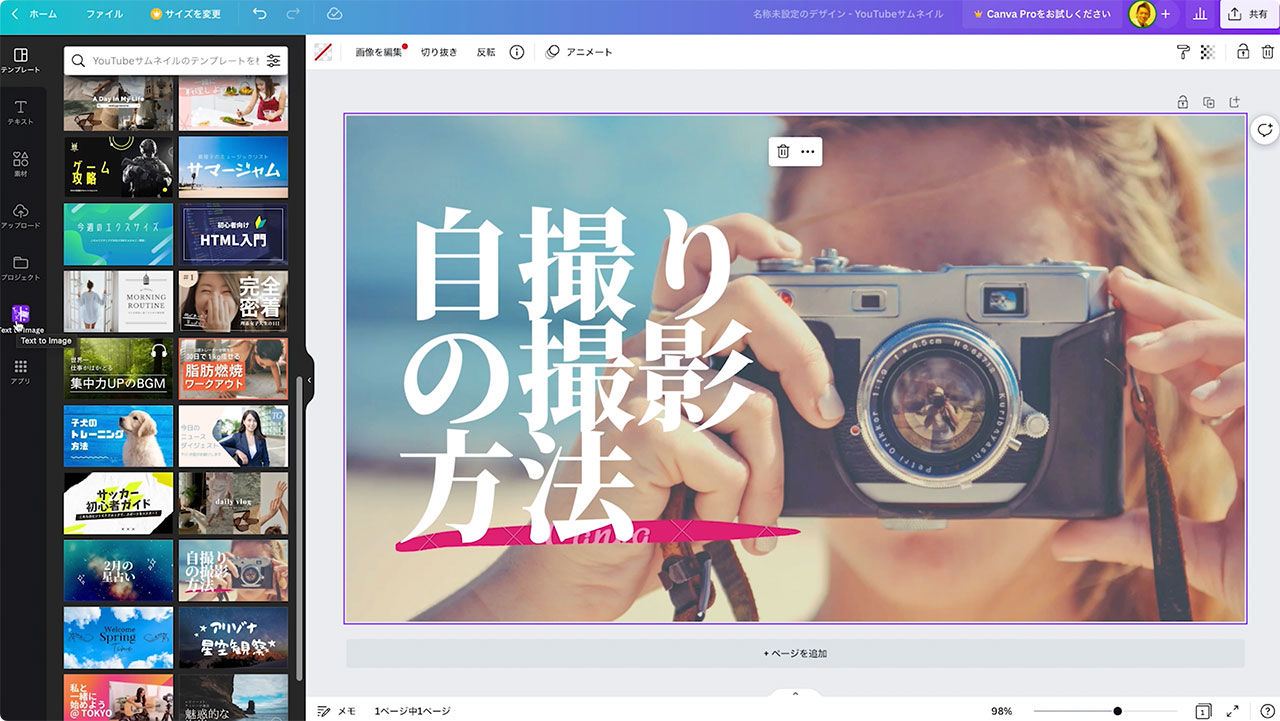
適当にテキストを入れましたが、これだけでもサムネ画像っぽくなりました。
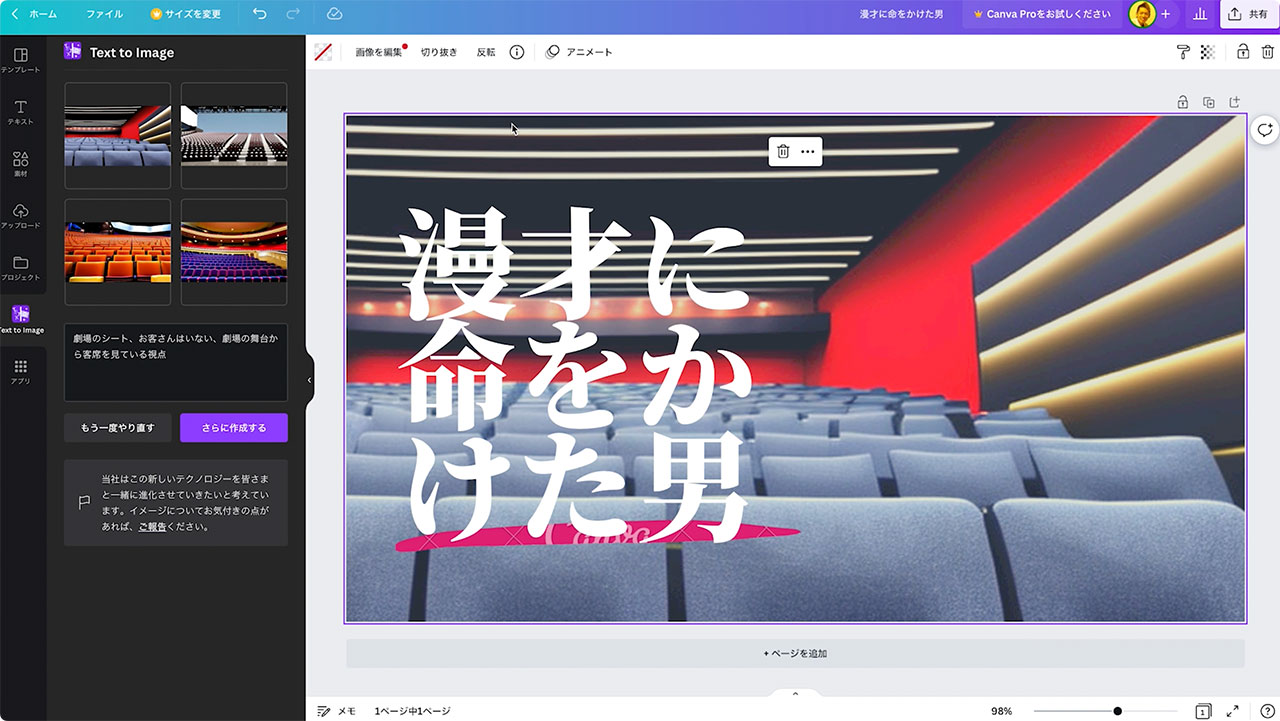
例5 漫才っぽいサムネ画像
もう少し漫才っぽい画像を作ってみます。「劇場の舞台に二人の男が立っている、その男たちの前には1本のマイクが置いてある」と入力してみました。
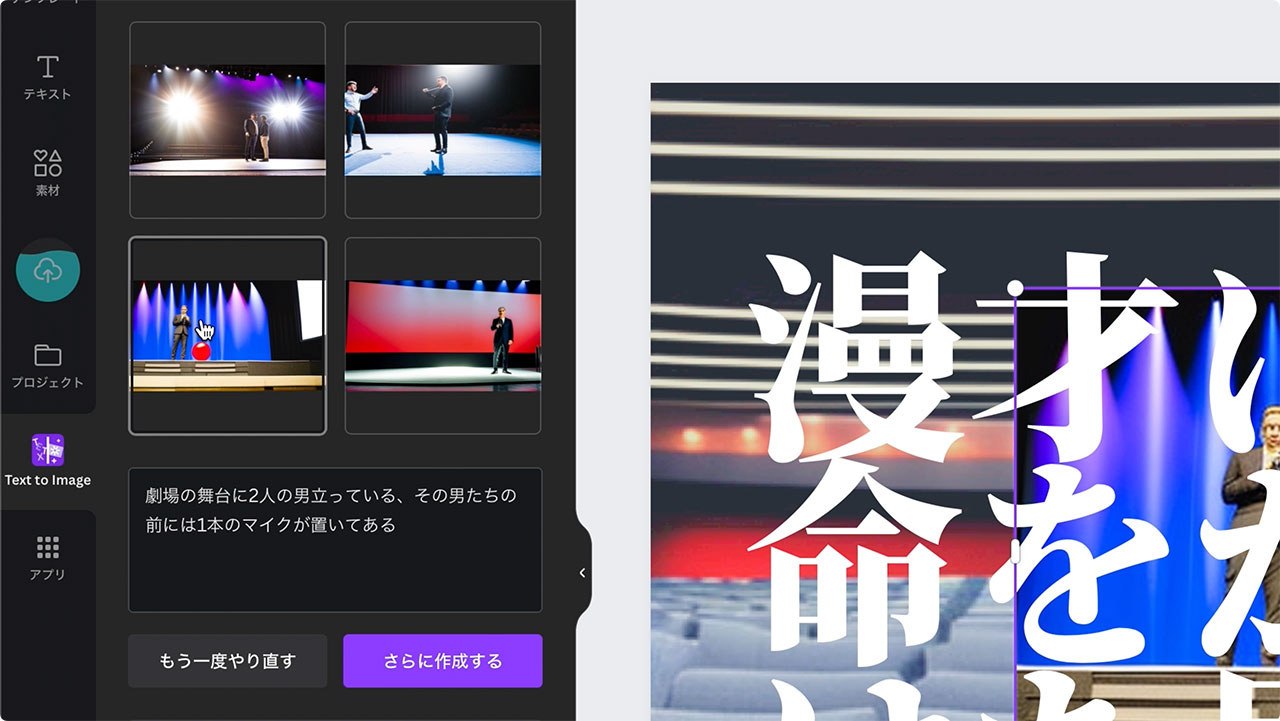
二人じゃなかったりマイクを手に持っていたりしますが、それでもそれっぽい画像が生成できました。
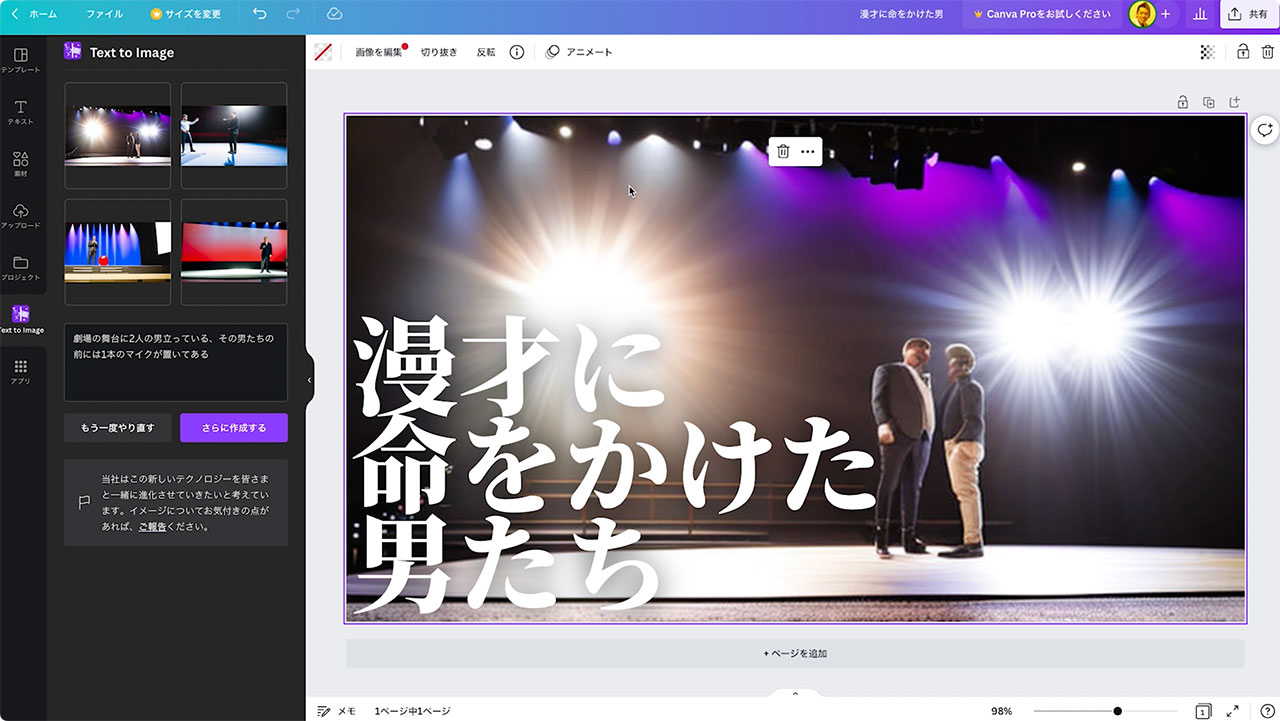
あとはテキストを書き変えたり、
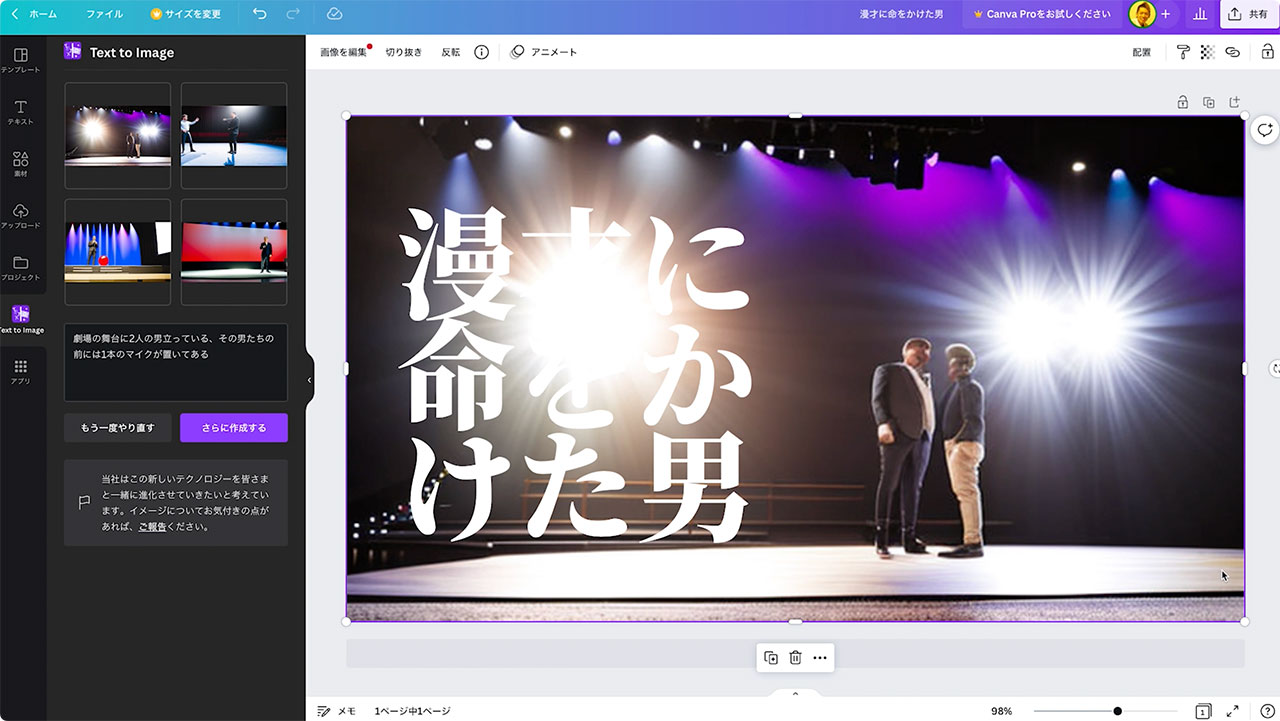
サイズを変えたり、エフェクトを調整していくだけで、サムネイル画像の完成です。
1日に生成できる枚数には上限がある
CanvaのText-to-Image機能は1日に生成できる枚数に上限があります。
先ほどの日本語入力途中に画像が生成されちゃう現象が起きてもカウントされてしまうので、なおさら気をつけたいところです。
この記事執筆現在では、1日に最大100個の画像を生成できるとのこと。1回で4枚生成されるので、25回分ですね。
画像だけダウンロードも可能
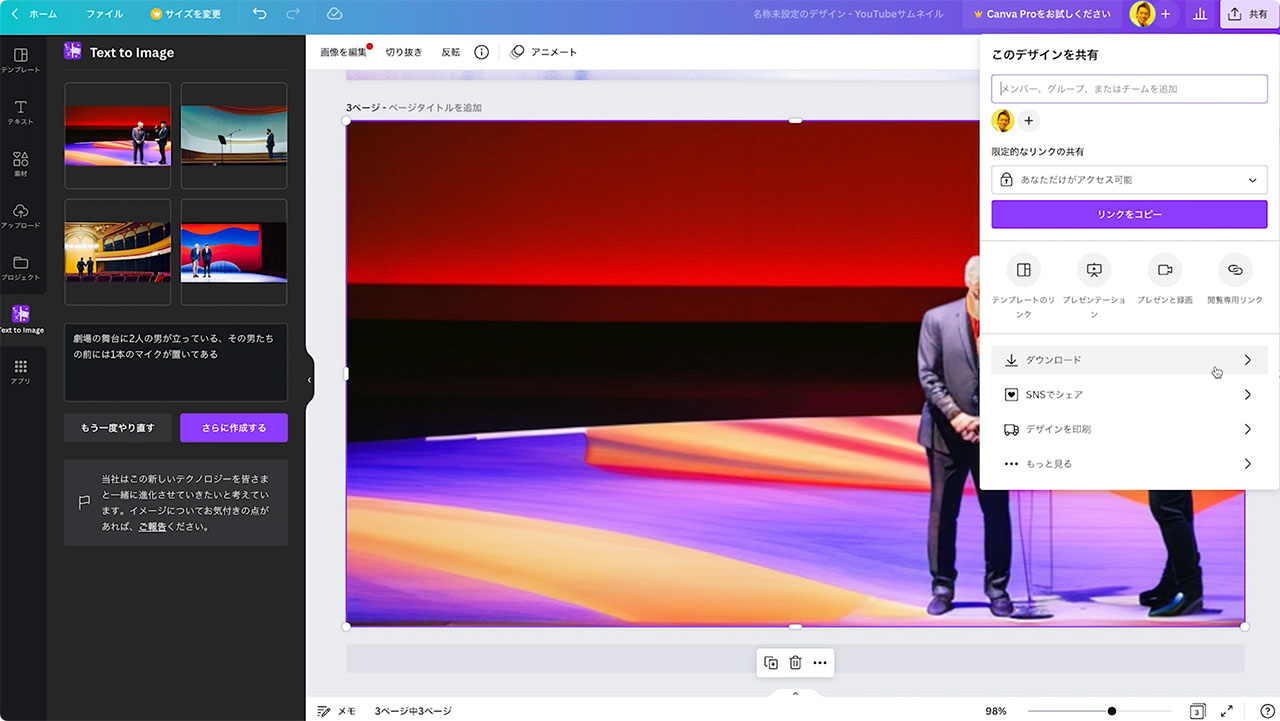
Canvaで全て仕上げてしまってもいいですが、生成された画像だけをダウンロードしたい場合は、テキストなどの他の要素を何も入れずにダウンロードすればOKです。
画面右上の共有ボタンからダウンロードのリンクで画像を保存できます。
日本語入力が可能なText-to-Imageサービスとして活用するだけでも十分便利だと思います。
最後に
Stable Diffusionを使った実験を繰り返して入力するプロンプトのコツをつかんできたものの、やはり母語である日本語での入力の方がコントロールがしやすいと感じます。
他のサービスでのAI画像生成がうまく行かなかった方はぜひ一度お試しください。